Data Relationship Schema
Introduction
The Data Relationship Schema is a table in AlchemyJ that is used for representing the relationship of the tables and would be used for constructing a data structure. It supports both single layer and multiple layers.
A REST API is always returning a JSON object with the definition of Data Relationship Schema. When the output data are multiple rows, the result will become a JSON Array. Then, it needs to create a root JSON node to convert them to a JSON object. For details, please refer to Example.
As for Java API, when the return class is an object, it would also depend on Data Relationship Schema to construct the object. There is no need to use Data Relationship Schema when the return value is a single value. For example, returning a customer's age.
Also, the Data Relationship Schema would be used in some AlchemyJ Extended Functions such as ajMakeXMLFromSchema and ajMakeJsonFromSchema.
To create a Data Relationship Schema, you can Go to the AlchemyJ toolbar, click on Insert Snippet and select Data Relationship Schema. A table would be inserted into the worksheet. The first row is the table header and there could be one more multiple records in the table. Each record is map to a table.
Column definition
| Column Name | Description |
|---|---|
| JSON Node Name (optional) | 1. This column is used to define the node name in the returned JSON/XML. 2. If this column is not included or the value is not keyed in, generate the node name automatically using table name with the following rule. a. Change the first character of 'Table' column value to lower case. b. Append "List" to the end if Multiple Row is TRUE. c. For example, if the 'Table' column value is 'Client' and 'Multiple Row' is TRUE, it will generate the node name as 'clientList'. |
| Table (required) | 1. Table name. It is a mandatory column and the value is mandatory. 2. There is no validation about the Table name. It could be a valid table name or Excel Defined Name or a random name. 3. The value should be unique in the schema relationship. 4. When the Schema table is used to define the function point input or output Object type parameter, the following rules will be checked. a. The Table name can only contain letters, numbers and underscores. It must start with a uppercase letter. b. The Table Name cannot be a Java or AlchemyJ reserved keyword. |
| Table Address (optional) | 1. The column is mandatory. 2. The column value is mandatory when any one of below situation happens: - Key is not empty. - The current table without sub-table. 3. The value is cell range address or Names, it is to get the table schema definition via the table address definition. 4. The table address has to include two rows at least, one column header and one data row. If the table address is not valid, it will return #VALUE!. 5. If the Table header and Table data body range is not in a continuous range, use asterisk "*" to join their addresses. For example: =ajGetAddress(A1:B1) & "*" & ajGetAddress(A10:B20) 6. If you would like to use high performance mode, you must use ajGetAddress UDF or Defined Name to define the table address. |
| Parent Table (optional) | 1. The column value is mandatory when Key is not empty for the current table. 2. Parent table name which is used to define the table dependency relationship 3. Parent table name should exist in 'Table' column value 4. If the parent table name doesn't exist in 'Table' column value, it will return #VALUE! 5. Parent Table name could not be the same as 'Table' in the same row. |
| Key (Conditional Mandatory) | 1. If the Parent Table is filled in and parent table records are more than 1 row, Key is mandatory. If the parent table only has one record, Key can be omitted because it means all records in sub-table will be joined. 2. If the Table Address of parent table is empty, Key can be omitted. 3. The key is mandatory when any of its parent tables at any level with Multiple Row = True. In this case, if the key value is not provided, it will return #VALUE!. 4. The Key is a column name in the parent table, the column name should be the same as the data name defined in the data dictionary. 5. If the Key is not provided when the parent table is filled in, it will return #VALUE! 6. If the Key value cannot be matched with any column name in the parent table, the column and data of the sub-table would not appear in the returned JSON/XML. |
| Multiple Row (optional) | 1. Boolean value - True / False, which is to define the records in the table is single or multiple. It can be inputted by the user or be calculated by the program. 2. If the value is provided by the user, it will follow the inputted value. 3. If this column is excluded or value is not inputted, check the number of body rows of the table a. Set to "True" if there is more than one body row in the Table associated range. b. Set to "False" if there is only one body row in the Table associated range. 4. If the inputted value is not a boolean value True / False, it will return #VALUE! |
| Data Dictionary Address (optional) | 1. The address of the Data Dictionary which defines the formatting rules. For example, DataDictionary!A11:Y21. Please include the header in the range of cells in the first row. When a data dictionary component is added to a workbook, it automatically creates a name, AlchemyJ_DataDic that specifies the data item list area. Thus, you can simply use [DataDictionarySheetName]!AlchemyJ_DataDic here. For example, if the data dictionary worksheet name is CustomerDataDic, the name here would be CustomerDataDic!AlchemyJ_DataDic. 2. It is used to format the value in the JSON/XML only and will not trigger data dictionary validation 3. When the Data Dictionary is provided, all columns should be included in the Data Dictionary. Otherwise, it will be omitted from the returned JSON/XML. 4. To enable the high performance mode, it must use ajGetAddress function to define the data dictionary. |
| Header Position(optional) | 1. To specify the table column header is in row-level or column level. a. top - the column header is in row-level b. left - the column header is in column level 2. Default is 'top' if no value is provided in the column |
| Required(optional) | TRUE - This table is mandatory and the information to be generated in the Open API specification. FALSE - This table is optional to be generated in the REST API Doc. Default is 'FALSE' if no value is provided in the column. |
| Description(optional) | Description to be shown in the Open API specification for this table. |
| API Model Name(optional) | API Model Name to be shown in the Open API specification for this table. |
If the cell value is Excel error (e.g. #VALUE!, #NA!, #DIV/0) in the data relationship schema table, the corresponding node would be omitted.
Example
Below are some samples to show how to use the data relationship table to return objects for API.
Assume there are two tables, Customer and Email.
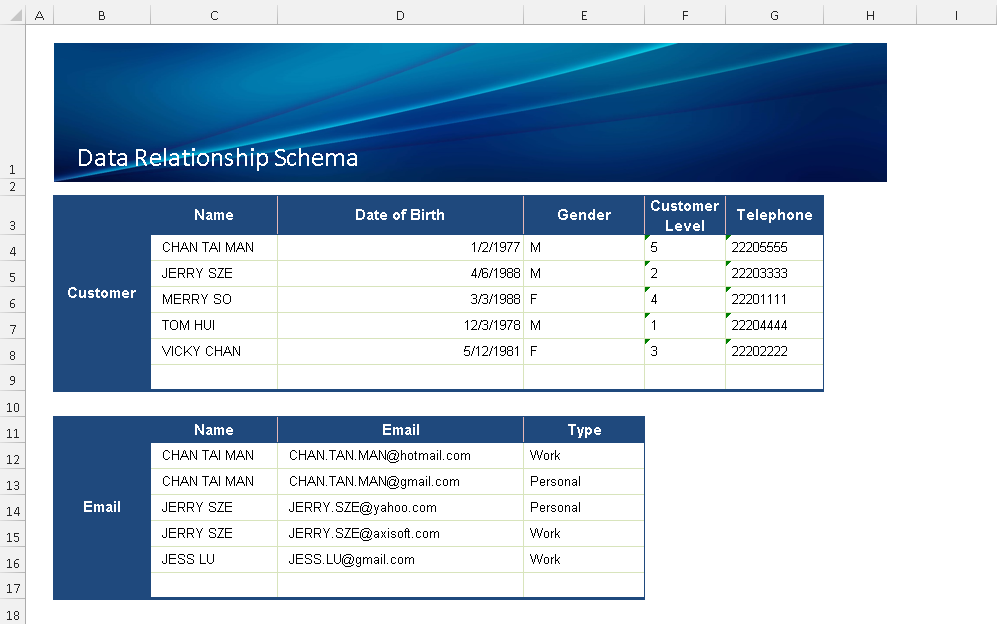
Sample 1 - Return a Single Customer Record
In this sample, it assumes that the REST API returns a customer record only. It only needs to define the Table and Table Address. For this case, the setting is the same for Java API.

Sample 2 - Return Multiple Customer Records
When the REST API needs to return multiple records, we need to add a root node to combine the JSON array into a JSON object. Besides the name and address for the customer table, we need to add a dummy table name in the first row and set it as the parent table. The dummy table is not required for Java API.

Sample 3 - Return Multiple Customer and Email Records
Similarly as Sample 2, the dummy table is required when it returns multiple objects. In this sample, it has appended the email table and the parent table is Customer. Since the email table needs to be linked with the Customer table, the key is required for it. For this case, the Name is the joint key for these two tables.
