DB Schema Worksheet
Introduction
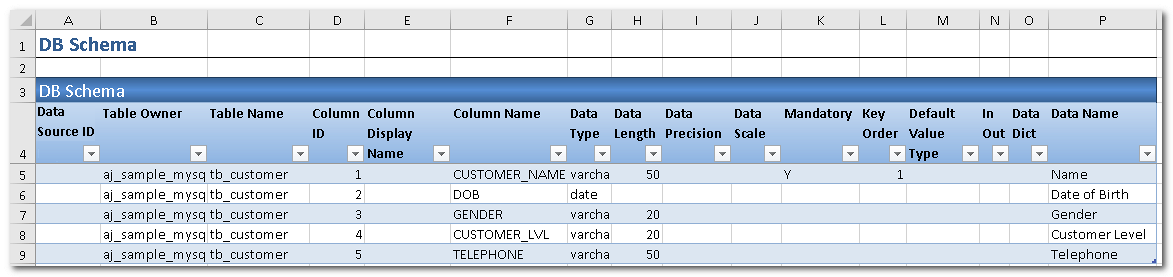
DB Schema is an AlchemyJ Component which links database tables and data dictionary in an AlchemyJ workbook.
To add the DB Schema worksheet, go to the AlchemyJ ribbon, click Add Component, select DB Schema.
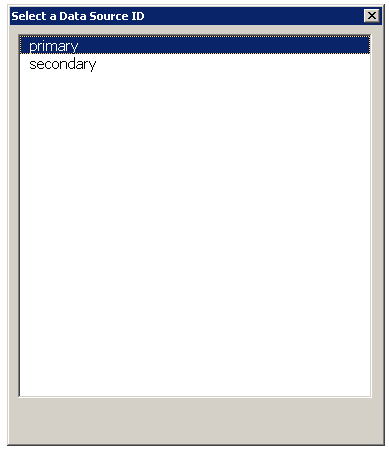
Input the name of the table you want to retrieve from your database. The table information will be loaded to the worksheet automatically. Before using this component, the database connection must be set up in the ##External Resources worksheet. Refer to Accessing database Recipe for an example.
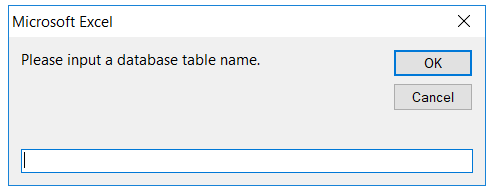
If there are more than one active data source, a dialog box will be shown for you to select the data source to use.
One DB Schema worksheet can contain multiple table schemas. To add a new table schema into an existing DB Schema worksheet, simply activate the DB Schema worksheet you would like to add, go to AlchemyJ ribbon, click Add Component, select DB Schema. AlchemyJ Studio will detect that the current worksheet is a DB Schema worksheet, then append the schema for a new table and will not create a new sheet.
DB Schema component can work with the following AlchemyJ Extended Functions.
- ajDBReadRecord
- ajDBCountRecord
- ajDBCreateRecord
- ajDBUpdateRecord
- ajDBMergeRecord
- ajDBDeleteRecord
- ajDBGetLOB
- ajDBUpdateLOB
Configuration
All columns are retrieved from the specified table except Data Dictionary Address and Data Name and Case Insensitive. These columns should be supplemented by the user.
| Configuration Item | Description |
|---|---|
| Data Source ID | String. The key name of Data Source. |
| Table Owner | String. The user name of the owner of the table. |
| Table Name | String. The name of the table. |
| Column ID | Integer. The unique ID of the column. |
| Column Display Name | String. The column name for display. |
| Column Name | String. The name of the column. |
| Data Type | String. Data Type of the column, it will be different depending on the database type. e.g. VARCHAR2, DATE, NUMBER, TIMESTAMP, FLOAT and so on. |
| Data Length | Integer. The length of the data. |
| Data Precision | Integer. The precision of the data. |
| Data Scale | Integer. The scale of the data. |
| Mandatory | It can be Y or empty. Y means the value must not be null. |
| Key Order | Integer. It could be empty or an integer. It specifies the order of the key column among other key columns. 1 is meaning this is the first key column. |
| Default Value Type | The type of default value when the value of the field is not provided. GUID - Assign a GUID. SQL - Calculate the default value by a SQL statement. AUTO_NUM - Assign a sequence number. |
| In Out | When the column has a default value, For Oracle and MSSQL database table, it will be set as InOut. For MySQL database table, it will be set as Out. If the column does not have a default value, it will be set as empty. |
| Mapped Data Type | String. Base on the column 'Data Type' value defined in different database, auto-fill in the unified data type definition in AlchemyJ. |
| Data Dictionary Address | The address of the Data Dictionary range in a Data Dictionary worksheet. It is recommended to use ajAddress so that the address can be updated automatically. |
| Data Name | The Data Name in Data Dictionary which this column maps to. |
| Case Insensitive | Whether this field of table is case sensitive when filtering or searching the DB records. Yes - Case Insensitive. No - Case Sensitive, Default is No. |
If the properties of a table has been changed, simply add the same table to DB Schema again (using Add Component\DB Schema). AlchemyJ will detect that the table exists already and will update the corresponding rows in the DB schema worksheet. Deleted columns will have an empty Column ID.