ajDBExportToWorkbook function
Available since AlchemyJ v4.1.3
Description
The ajDBExportToWorkbook function reads records from specified database table and writes to a specified range in the target workbook. Please take note that to run this function from Excel, you would need to set up the Data Source Connection in ##ExternalResources.
Syntax
ajDBExportToWorkbook(target_workbook_path, start_address, table_name, column_headers, [filter_type], [filter_condition], [sorting_criteria], [page_number], [rows_per_page], [table_schema], [transpose], [include_header], [data_source_id], [convert_to_text], [run_condition], [run_by_function_point_only])
| Argument Name | Argument Type | Description |
|---|---|---|
| target_workbook_path (required) | String | The path of the Excel file to be written. The function will create an Excel file automatically if the specified file path does not exist. Ensure that the current user has privilege to add/update files in the specified path. Remark: The function only supports the target workbook in xlsx and xlsm format and it cannot not be the same as the current workbook. |
| start_address (required) | String | The top-left cell of the range to write in the target workbook in the [sheet]!cell_address format. For example, "sheet1!A2". The function will check the range size in data_range to determine the actual range in the target workbook. |
| table_name (required) | String | The name of the table to read from. |
| column_headers (required) | Range / Array | The columns to be returned. It could be a range of single row or column where each cell is a table column name or a data name defined in DB Schema. CLOB and BLOB are not supported. |
| filter_type (optional) | Double | The type of filtering. 3 types are supported 0, 1 and 2. |
| filter_condition (optional) | Range / Array | The range that defines the filter condition. filter_type = 0. The range defines the WHERE clause of a SQL statement. The range will be concatenated into a single string. For example, Name = 'peter' and class = 'B'. filter_type = 1. The range defines the filter condition in the Kendo grid style. Click Insert Snippet\Filter Condition (Filter Type 1) to add the preset required format. filter_type =2. The range defines a filter condition similar to the format used in MS Query. Click Insert Snippet\Filter Condition (Filter Type 2) to add the preset required format. Refer to the Filter Condition snippet to see how you can use this snippet to define the required fields for filter type 1, 2. |
| sorting_criteria (optional) | Range / Array | The range which defines the sorting criteria. Refer to the Sorting Criteria Snippet to see how to use this snippet to define the required fields. |
| page_number (optional) | Double | The page of the returned records. It should be integer value, the decimal places will be rounded down if any. |
| rows_per_page (optional) | Double | The number of rows per page of the returned records. It should be integer value, the decimal places will be rounded down if any. Default is 100. |
| table_schema (optional) | Range / Array | The range that defines the DB Schema. |
| transpose (optional) | Boolean | If it equals FALSE, the return records will not be transposed. If it equals TRUE, the returned records will be transposed from row to column. The default value is FALSE. |
| include_header (optional) | Boolean | If it equals TRUE, the return result will include the column headers as the first row. If it equals FALSE, the return result will contain data only. The default value is FALSE. |
| data_source_id (optional) | String | The data source shall be used in this database operation. It shall be defined in ##ExternalResources worksheet. The default value is "primary". |
| convert_to_text (optional) | Boolean | If it equals TRUE, the return result will be converted to string values. If it equals FALSE, the return result will preserve the original data type. The default value is FALSE. |
| run_condition (optional) | Boolean | The function will run when the value is TRUE. Otherwise, it will not run. The default value is TRUE. |
| run_by_function_point_only (optional) | Boolean | If it equals FALSE, the function can be executed through ‘Excel Calculation’ (can be either Automatic or Manual, Calculate Now or Calculate Sheet) or Preview Function Point. If it equals TRUE, the function can be executed with Preview Function Point (AlchemyJ ribbon \ Preview Function Point) only. The default value is TRUE. |
The function will return:
1) Return Value: TRUE / #VALUE!
2) Return Type: Single Value
Example
ajDBExportToWorkbook is a combined function of ajDBReadRecord and ajWriteWorkbook.
We will use the following table as a example. The table name is tb_customer and it has 5 columns and 6 records.
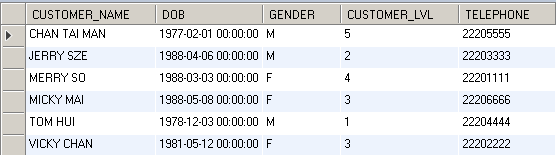
We use the formula below to export the data to a specified path. The first parameter is the target workbook name. If the specified file does not exist, it will create a new workbook in the specified path. Otherwise, it will update the content to the existing one.
=ajDBExportToWorkbook(B1,B2,B3,B4:F4,,,,,,,,B12,,,,B16)

The start address is sheet1!B2, so the content start from this cell. The column header were also shown since the include header is TRUE.

Error Scenarios
It will return #VALUE! when missing any required parameter or mismatch parameter type. Besides, system will raise error for below scenario(s).
| Error Scenario |
|---|
| Target workbook path is not a xlsx file or a xlsm file. |
| Invalid start address, it should be in [sheet name]![cell address] format. For example, sheet1!A2. |
| Failed to write workbook. |
| Target workbook is current workbook. |
| And/Or in filter condition is invalid. |
| Column header is not a single row range or a single column range. |
| Content in filter condition range does not meet the expected format of specified filter type. |
| Data name in filter condition does not exist in the provided table schema. |
| Data name in filter condition is empty. |
| Data name is empty. |
| DB connection error. |
| Filter type is invalid, it must be 0, 1, or 2. |
| Invalid operator value in filter condition. |
| Invalid page number, it must be greater than or equal to 1. |
| Invalid row per page, it must be greater than or equal to 1. |
| Invalid sorting criteria range. |
| Number of columns in column_headers does not match with the number of data columns. |
| Operator in filter condition is empty. |
| Sorting order in sorting criteria is not a number. |
| Table name does not exist in provided DB Schema. |
| Table name is empty. |
| The provided column header cannot be found in the specified table schema range. |
| The table schema columns are invalid. |
| The table schema range does not include a header or a row of data. |
| Total number of filter condition columns is not even number. |