ajUploadLob function
Description
The ajUploadLob function uploads a file to a Large Object (LOB) or a Character Large Object (CLOB) column in a database table. Please take note that to run this function from Excel, you would need to set up the DB Connection String from the Properties dialog box.
Syntax
ajUploadLob( table_name, lob_info, filter_type, filter_condition, table_schema, [data_source_id], [run_condition], [run_by_function_point_only] )
| Argument Name | Description |
|---|---|
| table_name (required) | The name of the table to store the file. |
| lob_info (required) | The range that contains the LOB field information. It can have 6 columns in the range with the following headers:
|
| filter_type (required) | The type of filter. The values can be 0, 1 or 2. |
| filter_condition (required) | The range that defines the filter condition. When filter_type = 0. The range defines the where clause of a SQL statement. The range will be concatenated into a single string. For example, Name = 'peter' and class = 'B'. filter_type = 1. The range defines the filter condition in the Kendo grid style. There are 6 columns in the range. The first row defines the header. They are Data Name, Operator 1, Search Criteria 1, And / Or, Operator 2, Search Criteria 2. The following operators are supported:
filter_type =2. The range defines a filter condition similar to the format used in MS Query. Two columns are used to define one filter condition. Therefore, the number of columns should always be a multiple of 2. E.g. 2, 4, 6. The first column defines the operator and the second column defines the value. For example, < 10 * Take note of the following: An error will occur if the range value is not in the format of the corresponding filter type. For filter_type = 1 or 2, if the operator is available but operand is empty, it will be treated as '' (i.e. empty string). If filter_type = 2, it will validate the Column Header and DataType against the database schema. |
| table_schema (required) | Specifies the range that defines the DB Schema. The key column(s) must be included in the Column_headers and Data. Otherwise, an error will be raised. |
| data_source_id (optional) | Specify the data source ID. The parameter is used to define which database should be executed for the function. If you do not specify anything, the default value will always be 'primary'. |
| run_condition (optional) | The function will run when the value is TRUE. Otherwise will not run. If you do not specify anything, the default value will always be TRUE. |
| run_by_function_point_only (optional) | If it equals FALSE, the function can be executed through ‘Excel Calculation’ (can be either Automatic or Manual, Calculate Now or Calculate Sheet) or Run Function Point. If it equals TRUE, the function can be executed with Run Function Point (AlchemyJ toolbar / Run Function Point) only. If you do not specify anything, the default value will always be TRUE. |
The function will return:
1) Content type: Number of affected records.
2) Method: Within a cell / cell array
Example
We will use the following table in our examples. The table name is tb_supporting_doc. It has 5 columns and 2 rows.
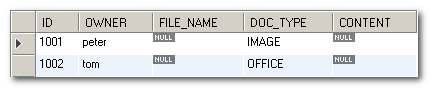
Upload the file to the CONTENT field of the record with ID 1001. 1 record is affected.



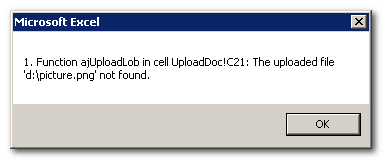
If the file is not found, an error message will appear.
Notes
- The column that stores the file should be a LOB (Large Object) or a CLOB (Character Large Object).
- Only one file can be stored in a LOB field.
- If the filter condition does not match anything, the function will return 0.
- If there are more than one record found, all matched records will be updated with the file.
- For more details about the filter options, you can refer to the ajReadRec function.